

UMAでメモリに使用される帯域幅は、単一のメモリコントローラを使用するため制限されています。 NUMAマシンの出現の主な動機は、複数のメモリコントローラを使用することによってメモリに利用可能な帯域幅を向上させることです。
比較表
| 比較基準 | UMA | ヌマ |
|---|---|---|
| 基本 | 単一のメモリコントローラを使用 | マルチメモリコントローラ |
| 使用されるバスの種類 | シングル、マルチ、クロスバー | ツリーと階層 |
| メモリアクセス時間 | 等しい | マイクロプロセッサの距離によって変わります。 |
| に適し | 汎用およびタイムシェアリングアプリケーション | リアルタイムでタイムクリティカルなアプリケーション |
| 速度 | もっとゆっくり | もっと早く |
| 帯域幅 | 限られた | UMA以上。 |
UMAの定義
UMA(Uniform Memory Access)システムは、マルチプロセッサ用の共有メモリアーキテクチャです。 このモデルでは、単一のメモリが相互接続ネットワークの助けを借りてマルチプロセッサシステムに存在するすべてのプロセッサによって使用されアクセスされる。 各プロセッサは、等しいメモリアクセス時間(待ち時間)およびアクセス速度を有する。 シングルバス、マルチバス、クロスバースイッチのどちらでも使用できます。 バランスのとれた共有メモリアクセスを提供するため、 SMP(Symmetric multiprocessor)システムとも呼ばれます。
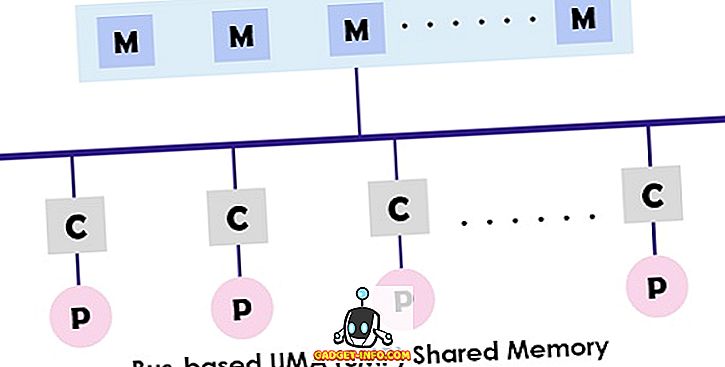
SMPの一般的な設計は、各プロセッサが最初にキャッシュに接続され、次にキャッシュがバスにリンクされる場合を示しています。 最後にバスはメモリに接続されます。 このUMAアーキテクチャは、個々の独立キャッシュから直接命令をフェッチすることでバスの競合を減らします。 それはまた、各プロセッサへの読み書きに対して等しい確率を提供する。 UMAモデルの典型的な例は、Sun Starfireサーバ、Compaq alphaサーバ、およびHP vシリーズです。
NUMAの定義
NUMA(Non-uniform Memory Access)も、各プロセッサが専用メモリに接続されているマルチプロセッサモデルです。 しかし、メモリのこれらの小さな部分が組み合わさって単一のアドレス空間を作ります。 ここで考えなければならない主な点は、UMAとは異なり、メモリのアクセス時間はプロセッサが配置されている距離に依存するため、メモリアクセス時間が変わることを意味します。 物理アドレスを使用して、任意のメモリ位置にアクセスできます。
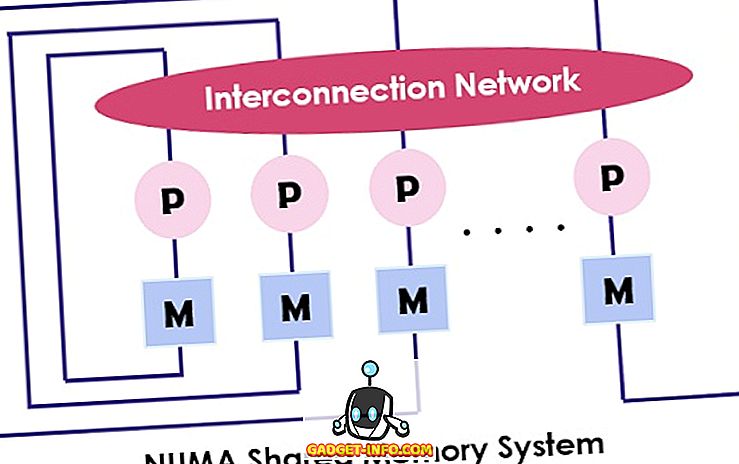
上述したように、NUMAアーキテクチャは、メモリに対して利用可能な帯域幅を増大させることを意図しており、そのために複数のメモリコントローラを使用している。 それは各コアがメモリコントローラを持つ「 ノード 」に多数のマシンコアを結合します。 NUMAマシンのローカルメモリにアクセスするために、コアはそのノードによってメモリコントローラによって管理されているメモリを取得します。 他のメモリコントローラによって処理されるリモートメモリにアクセスする間、コアは相互接続リンクを介してメモリ要求を送信する。
NUMAアーキテクチャは、ツリーと階層バスネットワークを使用して、メモリブロックとプロセッサを相互接続します。 BBN、TC-2000、SGI Origin 3000、Crayは、NUMAアーキテクチャの例です。
UMAとNUMAの主な違い
- UMA(共有メモリ)モデルは、1つまたは2つのメモリコントローラを使用します。 反対に、NUMAはメモリにアクセスするために複数のメモリコントローラを持つことができます。
- UMAアーキテクチャでは、シングル、マルチ、およびクロスバーバスが使用されます。 逆に、NUMAは階層型およびツリー型のバスとネットワーク接続を使用します。
- UMAでは、各プロセッサのメモリアクセス時間は同じですが、NUMAでは、プロセッサからのメモリの距離が変わるとメモリアクセス時間が変わります。
- 汎用および時分割アプリケーションはUMAマシンに適しています。 これとは対照的に、NUMAの適切なアプリケーションはリアルタイムでタイムクリティカルな中心です。
- UMAベースの並列システムは、NUMAシステムよりも動作が遅くなります。
- 帯域幅UMAに関しては、帯域幅を制限してください。 それどころか、NUMAはUMA以上の帯域幅を持っています。
結論
UMAアーキテクチャはメモリにアクセスするプロセッサに同じ全体的な待ち時間を提供します。 ローカルメモリがアクセスされるとき、待ち時間が均一になるので、これはあまり役に立ちません。 一方、NUMAでは、各プロセッサに専用メモリが搭載されているため、ローカルメモリにアクセスするときの待ち時間がなくなります。 プロセッサとメモリとの間の距離が変化するにつれて(すなわち、不均一)、待ち時間は変化する。 ただし、NUMAはUMAアーキテクチャと比較してパフォーマンスが向上しています。