


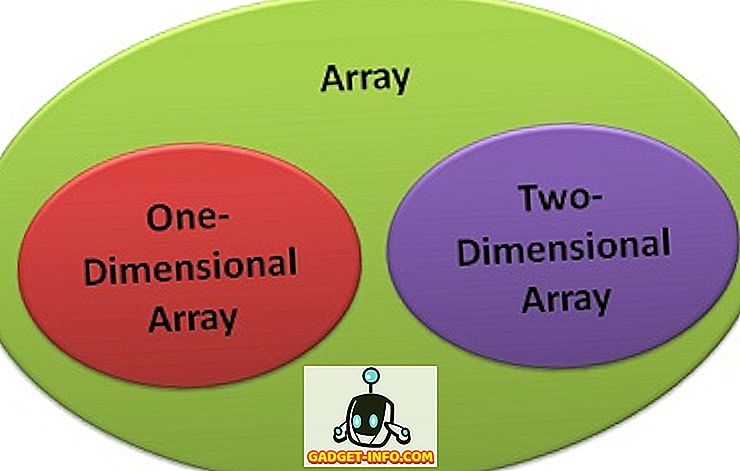
それでは比較チャートと一緒に一次元と二次元配列の違いから始めましょう。
比較表:
| 比較基準 | 一次元 | 二次元 |
|---|---|---|
| 基本 | 類似したデータ型の要素の単一リストを格納します。 | 「リストのリスト」、「配列の配列」、または「1次元配列の配列」を格納します。 |
| 宣言 | C ++での/ *宣言 type variable_name [size]; * / Javaでの/ *宣言 type variable_name []; variable_name =新しい型[サイズ]。 * / | C ++での/ *宣言 タイプvariable_name [size1] [size2]; * / Javaでの/ *宣言 type variable_name = new int [サイズ1] [サイズ2]; * / |
| 代替宣言 | / * Javaでは int [] a = new int [10]; * / | / * Javaでは int [] [] a = new int [10] [20]; * / |
| バイト単位の合計サイズ | 合計バイト数= sizeof(配列変数のデータ型)*配列のサイズ。 | 合計バイト数= sizeof(配列変数のデータ型)*最初のインデックスのサイズ* 2番目のインデックスのサイズ。 |
| 受信パラメータ | ポインタ、サイズ指定された配列、またはサイズ指定されていない配列で受け取ることができます。 | それを受け取るパラメータは、配列の右端の次元を定義しなければなりません。 |
| 寸法 | 一次元 | 二次元です。 |
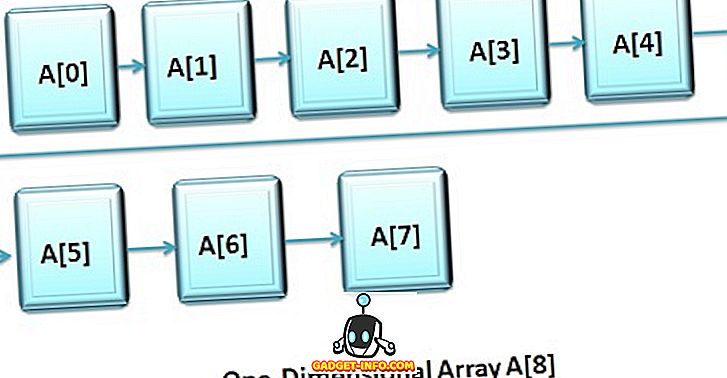
一次元配列(1-D配列)の定義
1次元配列または1次元配列は、「類似データ型の変数のリスト」と見なされます。各変数は、その配列の名前の前に角かっこでインデックスを指定することによって明確にアクセスできます。
C ++のコンテキストで議論しましょう
// C ++での宣言型variable_name [size];
ここでtypeは配列変数のデータ型を宣言し、sizeは配列が保持する要素の数を定義します。
たとえば、年の各月の残高を含む配列を宣言したいとします。
//例int month_balance [12];
Month _balanceは、各月の残高を表す12の整数を保持する配列変数です。 ここで、月の月数 'April'にアクセスしたい場合は、変数名の後に4月のインデックス値を含む角括弧、つまり 'month_balance [3]'を指定するだけです。 しかし 'April'が今年の4番目の月であるように私達は '[3]'を言及しました。なぜなら全ての配列はそれらの最初の要素のインデックスとして0を持つからです。
Javaでは、これは次のように実行できます。
// Java型での宣言variable_name []; variable_name =新しい型[サイズ]。
ここでは、最初にその型で配列変数を宣言してから、 'new'を使用して宣言された配列変数に 'new'を割り当ててメモリを割り当てました。 年の各月の残高を含む配列を宣言したい場合は、上記の例を見てみましょう。
//例int month_balance []; month_balance = new int [12];
ここで、 'new'は配列変数 "month_balance"にメモリを割り当てるので、今度はmont_balanceは12個の整数値に対してメモリを保持するようになります。
配列は宣言時に初期化できます。 配列初期化子は、中括弧で囲まれたコンマ区切り値のリストです。
//例
int month_balance = {100、500、200、750、850、250、630、248、790、360、450、180}; 二次元配列(2次元配列)の定義
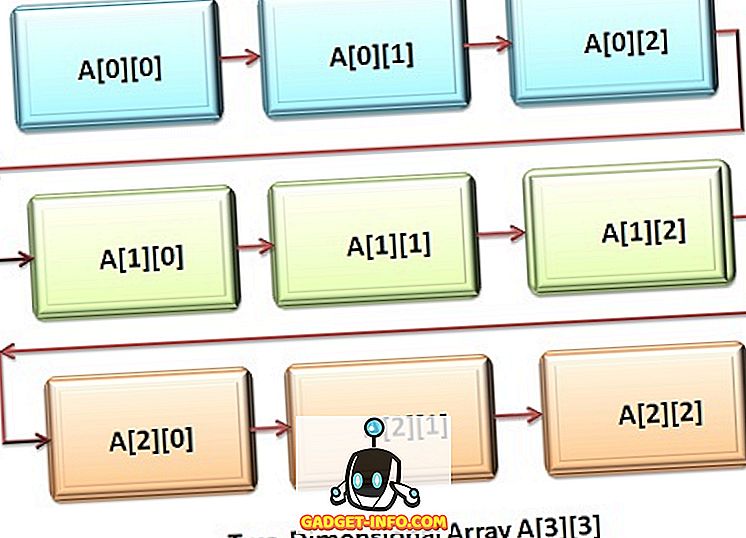
C ++とJavaはどちらも多次元配列をサポートしています。 多次元配列の最も単純な形式の1つは、2次元配列または2次元配列です。 二次元配列は、「配列の配列」または「一次元配列の配列」と見なすことができます。 2次元配列変数を宣言するには、配列名とそれに続く2つの角括弧を指定する必要があります。ここで、2番目のインデックスは2番目の角括弧のセットです。
2次元配列は、行と列の行列の形式で格納されます。ここで、最初のインデックスは行を示し、2番目のインデックスは列を示します。 配列の要素にアクセスしている間、配列の2番目または右端のインデックスは、最初または左端のインデックスと比べて非常に速く変化します。
// C ++での宣言type variable_name [size1] [size2];
たとえば、1年の各月の30日ごとの残高を2次元配列で格納したいとします。
// example int month_balance [12] [30];
Javaでは、2次元配列は次のようになります。
// Java型での宣言型variable_name = new int [サイズ1] [サイズ2]; //例int month_balance = new int [12] [30];
配列全体をパラメータとして関数に渡すことはできないので、配列の最初の要素へのポインタが渡されます。 2次元配列を受け取る引数は、それを右端の次元として定義しなければなりません。 配列を正しくインデックス付けする場合は、各行の長さを確認するためにコンパイラが必要とするため、右端の次元が必要です。 右端のインデックスが指定されていないと、コンパイラは次の行の開始位置を判断できません。
// Javaの例void receiveing_funct(int a [] [10]){。 。 。 } メモリがJavaの2次元配列に動的に割り当てられているときは、一番左のインデックスが指定され、残りの次元は別々に割り当てることができます。つまり、配列のすべての行が同じサイズではない場合があります。
// Javaの例int month_balance = new int [12] []; month_balance [0] = new int [31]; month_balance [1] = new int [28]; month_balance [2] = new int [31]; month_balance [3] = new int [30]; month_balance [4] = new int [31]; month_balance [5] = new int [30]; month_balance [6] = new int [31]; month_balance [7] = new int [30]; month_balance [8] = new int [31]; month_balance [9] = new int [30]; month_balance [10] = new int [31]; month_balance [11] = new int [30]; month_balance [12] = new int [31];
しかし、そうすることの利点はありません。
一次元配列と二次元配列の主な違い
- 1次元配列は、要素が同じデータ型のリストです。 一方、2次元配列は、要素が類似したデータ型の配列であるリストです。
- C ++では、一次元配列が受け取り関数のパラメータによって受け取られるとき、配列のサイズを言及する必要はありません。受け取られることです。 2次元配列では、コンパイラは単一行の終わりと新しい行の始まりを知る必要があるため、2番目または右端のインデックスを指定します。
- C ++では、1次元配列はインデックス付きの順序で連続したメモリ位置に格納されますが、2次元配列も連続したメモリ位置に格納されますが、2次元配列には複数の行があるため、最初の行の後には2番目と3番目などが続きます。
注意:
1次元配列と2次元配列の両方を関数に渡すことは似ています。つまり、両方とも配列の名前だけで渡されます。
// passing_funt(name_of_array);の例
結論:
一次元配列でも二次元配列でも、インデックスは配列内の要素を明確に識別する唯一のものであるため、非常に重要な役割を果たします。 一次元配列と二次元配列は宣言時に初期化することができます。






