

明らかに、人間とコンピュータのような電子機器の知覚性は異なります。 人間は自然言語を通して何でも理解することができますが、コンピュータは理解しません。 コンピュータは、人間が読める形式で書かれた言語をコンピュータで読める形式に変換する翻訳者を必要とします。
コンパイラとインタプリタは言語トランスレータの種類です。 言語翻訳者とは何ですか? この質問はあなたの心の中で起こっているかもしれません。
言語翻訳プログラムは、人間が読める形式のプログラムをソース言語からオブジェクト言語の同等のプログラムに翻訳するソフトウェアです。 ソース言語は一般に高級プログラミング言語であり、オブジェクト言語は通常実際のコンピュータの機械語である。
比較表
| 比較基準 | コンパイラ | 通訳 |
|---|---|---|
| 入力 | それは一度にプログラム全体を取ります。 | 一度に1行のコードまたは命令が必要です。 |
| 出力 | 中間オブジェクトコードを生成します。 | 中間オブジェクトコードは生成されません。 |
| 働きメカニズム | コンパイルは実行前に行われます。 | コンパイルと実行は同時に行われます。 |
| 速度 | 比較的速い | もっとゆっくり |
| 記憶 | メモリ要件は、オブジェクトコードの作成によるものです。 | 中間オブジェクトコードを作成しないため、必要なメモリが少なくて済みます。 |
| エラー | コンパイル後にすべてのエラーをすべて同時に表示します。 | 各行のエラーを1行ずつ表示します。 |
| エラー検出 | 難しい | 比較的簡単 |
| 関連するプログラミング言語 | C、C ++、C#、Scala、タイプスクリプトはコンパイラを使用します。 | Java、PHP、Perl、Python、Rubyはインタプリタを使います。 |
コンパイラの定義
コンパイラは、高水準言語で書かれたプログラムを読み取り、それを機械語または低水準言語に変換し、プログラムに存在するエラーを報告するプログラムです。 ソースコード全体を一度に変換するか、複数のパスを使用して変換することもできますが、最後に、ユーザーはコンパイルされたコードを取得して実行する準備が整います。

コンパイラはフェーズで動作します。 さまざまな段階を次の2つの部分に分類できます。
- コンパイラの分析フェーズはフロントエンドとも呼ばれ、プログラムは基本的な構成部分に分割され、中間コードが生成された後にコードの文法、意味、構文をチェックします。 分析フェーズには、字句解析プログラム、セマンティック解析プログラム、および構文解析プログラムが含まれます。
- コンパイラの合成フェーズは、中間コードが最適化され、ターゲットコードが生成されるバックエンドとしても知られています。 合成フェーズには、コードオプティマイザとコードジェネレータが含まれます。
コンパイラのフェーズ
それでは各段階の働きを詳細に理解しましょう。
- 字句解析プログラム:コードを文字のストリームとしてスキャンし、文字のシーケンスを語彙素にグループ化し、プログラミング言語を参照して一連のトークンを出力します。
- 構文アナライザー :このフェーズでは、前の段階で生成されたトークンが、式が構文的に正しいかどうかにかかわらず、プログラミング言語の文法と照合されます。 そうすることで木を解析します。
- Semantic Analyzer :前のフェーズで生成された式やステートメントがプログラミング言語の規則に従っているかどうかを検証し、注釈付きの構文解析ツリーを作成します。
- 中間コード生成プログラム :ソースコードと同等の中間コードを生成します。 中間コードの表現は多数ありますが、TAC(Three Address Code)が最も広く使用されています。
- コードオプティマイザー :プログラムの時間とスペースの要件を改善します。 そうするために、それはプログラムに存在する冗長なコードを排除します。
- コードジェネレータ :これは、特定のマシン用のターゲットコードが生成されるコンパイラの最終段階です。 メモリ管理、レジスタ割り当て、マシン固有の最適化などの操作を実行します。
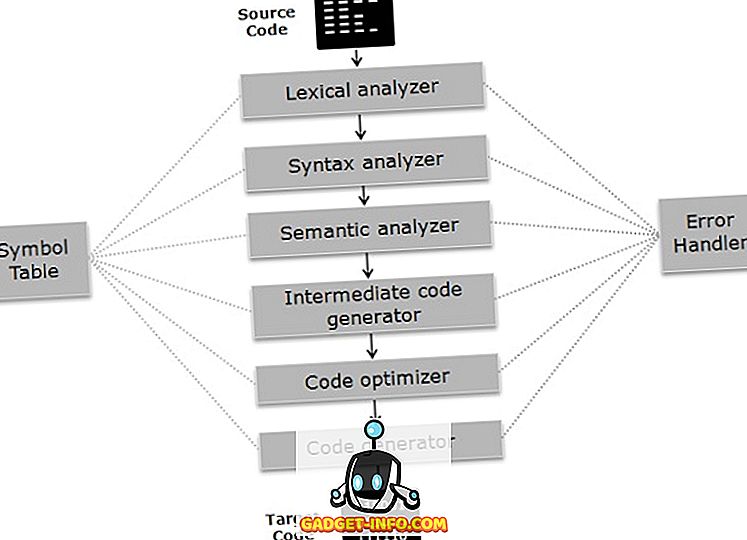
シンボルテーブルは、それが格納している適切な種類のデータと共に識別子を管理するデータ構造です。 エラーハンドラは、コンパイラのさまざまな段階の間に発生したエラーを検出、報告、修正します。
通訳者の定義
インタプリタはプログラミング言語を実装するための代替手段であり、コンパイラと同じ働きをします。 インタプリタは、コンパイラと同様に、 字句 解析 、 解析および型チェックを実行します。 しかし、インタプリタは、構文ツリーからコードを生成するのではなく、構文ツリーを直接処理して式にアクセスし文を実行します。
インタプリタは同じ構文木を複数回処理する必要があるかもしれません、それは解釈がコンパイルされたプログラムを実行するより比較的遅い理由です。
コンパイルと解釈はおそらくプログラミング言語を実装するために組み合わされました。 コンパイラが中間レベルのコードを生成する場合、コードはマシンコードにコンパイルされるのではなく解釈されます。
インタプリタを使用することはプログラム開発の間有利です、最も重要な部分はプログラムを効率的に走らせるよりむしろプログラム修正を急速にテストすることができることです。
コンパイラとインタプリタの主な違い
コンパイラとインタプリタの主な違いを見てみましょう。
- コンパイラはプログラム全体を受け取り、それを翻訳しますが、インタプリタはプログラムをステートメントごとに翻訳します。
- コンパイラの場合は、中間コードまたはターゲットコードが生成されます。 インタプリタに対して中間コードを作成しません。
- コンパイラはプログラム全体を一度に処理するため、コンパイラはインタープリタよりも比較的高速です。インタープリタはコードの各行を順にコンパイルします。
- オブジェクトコードが生成されるため、コンパイラはインタプリタよりも多くのメモリを必要とします。
- コンパイラはすべてのエラーを同時に表示します。対照的なインタプリタでは各ステートメントのエラーを1つずつ表示してエラーを検出するのは困難であり、エラーを検出する方が簡単です。
- コンパイラでは、プログラム内でエラーが発生した場合、その翻訳を停止し、エラーを取り除いた後、プログラム全体が再び翻訳されます。 逆に、インタープリタでエラーが発生すると、その変換は妨げられ、エラーを取り除いた後で変換が再開されます。
- コンパイラでは、このプロセスには2つのステップが必要です。最初にソースコードがターゲットプログラムに変換されてから実行されます。 通訳者の間それはソースコードが同時にコンパイルされ実行されるワンステッププロセスです。
- コンパイラは、C、C ++、C#、Scalaなどのプログラミング言語で使用されます。他のインタプリタは、Java、PHP、Ruby、Pythonなどの言語で使用されます。
結論
コンパイラとインタプリタはどちらも同じ作業を実行することを意図していますが、操作手順が異なります。コンパイラはソースコードを集約的に取りますが、インタプリタはソースコードの構成部分、つまりステートメントごとを取ります。
コンパイラとインタプリタはどちらも長所と短所がありますが、インタプリタ言語はクロスプラットフォームと見なされます。つまり、コードは移植可能です。 時間を節約するコンパイラとは異なり、以前に命令をコンパイルする必要もありません。 コンパイルされた言語はコンパイルプロセスに関しては速いです。