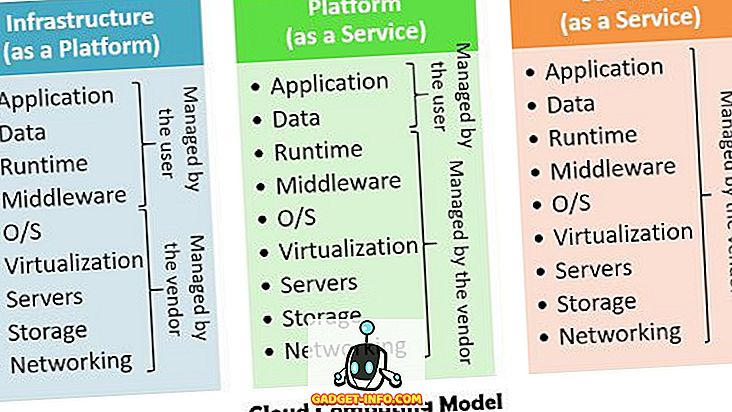
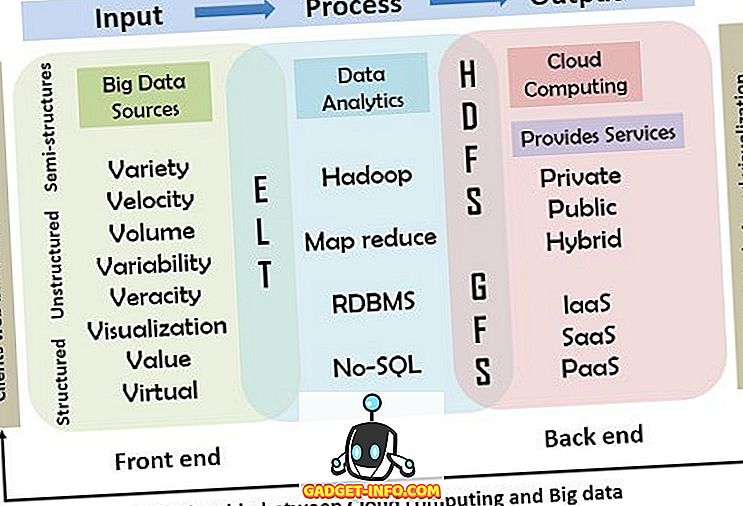
それは以下に説明される入力、処理および出力モデルを含む。 この図は、クラウドコンピューティングとビッグデータの関係を詳細に示しています。
比較表
| 比較基準 | クラウドコンピューティング | ビッグデータ |
|---|---|---|
| 基本 | オンデマンドサービスは、統合されたコンピュータリソースとシステムを使用して提供されます。 | 従来の処理手法では処理できない、構造化された、構造化されていない、複雑なデータの広範なセット。 |
| 目的 | データをリモートサーバーに保存して処理し、任意の場所からアクセスできるようにします。 | 大量のデータと情報を整理して抽出することで、貴重な知識を隠しました。 |
| ワーキング | 分散コンピューティングは、データを分析してより有用なデータを生成するために使用されます。 | インターネットはクラウドベースのサービスを提供するために使用されます。 |
| 利点 | 低メンテナンス費用、集中型プラットフォーム、バックアップとリカバリのための準備。 | 費用対効果の高い並列処理、拡張性、堅牢性 |
| 課題 | 可用性、変換、セキュリティ、課金モデル | データの多様性、データ保存、データ統合、データ処理、およびリソース管理。 |
クラウドコンピューティングの定義
クラウドコンピューティングは、高速インターネットを使用してオンデマンドで、いつでもどこからでも任意の量のデータを格納および取得するためのサービスの統合プラットフォームを提供します。 クラウドは、データを保存、管理、および処理するためにインターネット全体に分散している幅広い地上サーバーのセットです。 クラウドコンピューティングは、開発者がWeb規模のコンピューティングを容易に実装できるように開発されています。 インターネットはクラウドコンピューティングの基盤であるため、インターネットの進化はクラウドコンピューティングモデルを生み出しました。 クラウドコンピューティングを効率的に機能させるには、高速インターネット接続が必要です。 それは柔軟性のある環境を提供し、そこでは容量と能力が動的に追加され、そして使用ごとの支払い戦略に従って使用されることができます。
クラウドコンピューティングには、リソースプーリング、オンデマンドセルフサービス、幅広いネットワークアクセス、測定されたサービス、および迅速な弾力性など、いくつかの重要な特性があります。 クラウドには、パブリック、プライベート、ハイブリッド、コミュニティの4種類があります。
基本的に3つのクラウドコンピューティングモデルがあります - サービスとしてのプラットフォーム(Paa)、サービスとしてのインフラストラクチャ(Iaas)、ソフトウェアとしてのサービス(Saas)、そしてハードウェアとソフトウェアサービスを使用します。
- サービスとしてのインフラストラクチャ - このサービスは、ストレージ処理能力と仮想マシンを含むインフラストラクチャを提供するために使用されます。 サービスレベル契約(SLA)に基づいてリソースの仮想化を実装します。
- サービスとしてのプラットフォーム - IaaS層の上にあり、ユーザーがクラウドアプリケーションをデプロイできるようにするためのプログラミングおよびランタイム環境を提供します。
- サービスとしてのソフトウェア - クラウドプロバイダー上で直接実行されるアプリケーションをクライアントに配信します。

ビッグデータの定義
データは、ITシステムの能力を超えてボリューム、種類、速度が増加するにつれてビッグデータに変わります。その結果、データの保存、分析、処理が困難になります。 この種の大量の構造化データを処理するための機器と専門技術を開発した組織もありますが、指数関数的に増加するデータ量と迅速なデータフローにより、それをマイニングして迅速に実用的な情報を生成することはできません。 この膨大なデータを通常のデバイスに格納して分散環境に分散させることはできません。 ビッグデータコンピューティングは、大規模インフラストラクチャ上での科学的発見とビジネス分析のための多次元情報マイニングに集中するデータ科学の最初の概念です。
ビッグデータの基本的な次元はボリューム、ベロシティ、バラエティそして真実性であり、これらも上記の通りですが、後になってさらに2つの次元、すなわち可変性と価値が生まれます。
- ボリューム - データを処理して保存するのにすでに問題があるデータのサイズの増加を示します。
- 速度 - データが取り込まれるインスタンスとデータの流れの速度です。
- バラエティ - データは常に単一の形式で表示されるわけではありません。たとえば、テキスト、音声、画像、ビデオなど、さまざまな形式のデータがあります。
- 真実性 - データの信頼性と呼ばれます。
- 変動性 - ビッグデータに生じる信頼性、複雑さ、および矛盾について説明します。
- 価値 - コンテンツの元の形式はそれほど有用で生産的ではないかもしれないので、データが分析され、価値の高いデータが発見されます。
クラウドコンピューティングとビッグデータの主な違い
- クラウドコンピューティングは、インターネット上に分散したコンピューティングリソースを使用してオンデマンドで配信されるコンピューティングサービスです。 一方、ビッグデータは、従来のアルゴリズムや手法では処理できない、構造化データ、非構造化データ、半構造化データを含む大量のコンピュータデータです。
- クラウドコンピューティングは、Saas、Paas、Iaasなどのサービスをオンデマンドで利用するためのプラットフォームをユーザーに提供します。また、用途に応じてサービスに対して課金します。 対照的に、ビッグデータの主な目的は、膨大なデータの集まりから隠された知識やパターンを抽出することです。
- 高速インターネット接続は、クラウドコンピューティングに不可欠な要件です。 反対に、ビッグデータはデータを分析しマイニングするために分散コンピューティングを使用します。
クラウドコンピューティングとビッグデータの関係
以下の図は、ビッグデータとクラウドコンピューティングの関係と動作を示しています。 このモデルでは、マウス、キーボード、携帯電話、その他のスマートデバイスなどの入力デバイスを使用してビッグデータがシステムに挿入される参照として、主な入力、処理、および出力コンピューティングモデルが使用されます。 処理の第2段階には、サービスを提供するためにクラウドで使用されるツールと技術が含まれます。 最後に、処理結果がユーザーに配信されます。
結論
クラウドコンピューティングテクノロジは、使いやすさ、リソースへのアクセス、需要と供給によるリソース使用の低コストによってビッグデータに適した準拠フレームワークを提供し、ビッグデータの処理に使用される堅牢な機器の使用を最小限に抑えます。 クラウドとビッグデータはどちらも、投資コストを削減しながら企業の価値を高めることに重点を置いています。