
比較表
| 比較基準 | 文字配列 | ひも |
|---|---|---|
| 基本 | 文字配列は、文字データ型の変数の集まりです。 | Stringはクラスで、stringの変数はクラス "string"のオブジェクトです。 |
| 構文 | char array_name [size]; | 文字列string_name; |
| 索引付け | 文字配列内の個々の文字は、配列内のインデックスによってアクセスできます。 | stringでは、特定の文字は関数 "string_name.charAt(index)"によってアクセスすることができます。 |
| データ・タイプ | 文字配列はデータ型を定義しません。 | 文字列はC ++でデータ型を定義します。 |
| オペレータ | C ++の演算子は文字配列には適用できません。 | 標準のC ++演算子を文字列に適用することができます。 |
| 境界 | 配列境界は簡単にオーバーランします。 | 境界はオーバーランしません。 |
| アクセス | 高速アクセス | アクセスが遅い |
文字配列の定義
文字配列は、“ char”データ型の変数の集まりです。 それは一次元配列または二次元配列であり得る。 これは、「NULL終端文字列」とも呼ばれます。 文字配列は、連続したメモリアドレスに格納されている文字のシーケンスです。 文字配列では、特定の文字はそのインデックスによってアクセスできます。 「NULL文字」は、文字配列を終了させます。

文字配列の例を見てみましょう: -
char name [] = {'A'、 'j'、 'a'、 'y'、 '\ 0'}; またはchar name [] = "Ajay"; ここで、“ char”は文字データ型、“ name”は文字配列の変数名です。 文字配列を初期化する2つの方法を示しました。 最初の方法ではnullが明示的に言及され、2番目の方法ではコンパイラが自動的にnullを挿入します。
文字列の末尾は常にNULL文字です。 これは文字配列の終端文字です。 文字配列は組み込みデータ型ではありません。 宣言して文字配列を作成します。 標準の演算子を文字配列に適用することはできません。 文字配列を操作するために、(strlen()、strlwr()、strupr()、strcat())などの組み込み関数があります。 標準演算子は文字配列には適用できないため、どの演算式にも参加できません。
文字配列への文字ポインタも作成できます。
例でそれを理解しましょう。
char s1 [] = "こんにちは"; char s2 [] = "Sir"; s1 = s1 + s2。 //エラー演算子は適用できませんs2 = s1; //エラー文字ポインタchar * s = "Morning"; char * p; p = s。 //実行
上記の例では、2つの文字配列s1、s2と2つの文字ポインタs、pを宣言しました。 文字配列s1とs2は初期化され、加算演算子(+)も代入演算子も文字配列に対して機能していないことがわかります。 しかし、文字ポインタを他の文字ポインタに割り当てることができます。
一度文字配列が初期化されると、それを別の文字セットに再び初期化することはできません。 文字配列またはNULLで終わる文字列へのアクセスは、C ++の文字列と比べて高速です。
文字列の定義
文字列はC ++の組み込みデータ型ではありません。 それは型 "文字列"のクラスオブジェクトです。 C ++の場合と同様に、クラスの作成は「型」の作成に似ています。 クラス“ string”はC ++ライブラリの一部です。 それは全体として文字または文字配列のセットを保持します。 標準文字列クラスの開発には3つの理由があります。
- 1つは「一貫性」です。文字配列はそれ自体ではデータ型ではありません。
- 2つ目は「便利さ」です。文字配列に対して標準の演算子を使用することはできません。
- 3つ目は「安全性」です。配列の境界は簡単にオーバーランします。
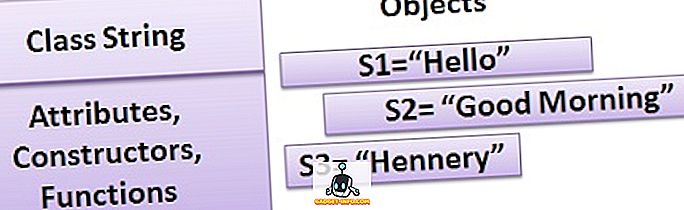
例を使って文字列を理解しましょう。
文字列s1。 s1 = "こんにちは"; 文字列s2( "おはよう")。 ストリングs3 = "Hennery"; 文字列s4。
上記の宣言では、4つの文字列変数またはオブジェクト(s1、s2、s3、s4)が宣言されています。 上記の宣言では、文字列を初期化する3つの方法を示しました。 文字列s1が宣言され、その後個別に初期化されます。 文字列s2は、クラス "String"のコンストラクタによって初期化されます。 文字列s3は、通常のデータ型と同様に、宣言時に初期化されます。 標準の演算子を文字列変数に適用できます。
s4 = s1; //ある文字列オブジェクトを他の文字列オブジェクトに代入するs4 = s1 + s2; //(s3> s2)の場合、// 2つの文字列を加算して3番目の文字列に格納する。 既存の文字列オブジェクトを使って新しい文字列オブジェクトを作成する
上記のコードでは、さまざまな演算子が文字列に適用され、さまざまな操作が実行されます。 最初のステートメントは、ある文字列オブジェクトを別の文字列オブジェクトにコピーします。 2番目のステートメントでは、2つのストリングが連結され、3番目のストリングに保管されています。 3番目のステートメントでは、2つのストリングが比較されています。 4番目のステートメントでは、既存の文字列オブジェクトを使って新しい文字列オブジェクトを作成します。
文字列へのアクセスは、文字配列またはNULLで終わる文字列と比べて遅くなります。
文字配列と文字列の主な違い
- 文字配列は、文字データ型の変数の集まりです。 Stringは、文字列を宣言するためにインスタンス化されたクラスです。
- インデックス値を使用すると、文字配列から文字にアクセスできます。 一方、文字列内の特定の文字にアクセスしたい場合は、関数string's_name.charAt(index)でアクセスできます。
- 配列は同様にデータ型ではないので、文字もデータ型ではありません。 一方、クラスであるStringは参照型として機能するため、Stringはデータ型であると言えます。
- 文字配列に演算子を適用することはできませんが、Stringに演算子を適用することはできます。
- 配列である文字配列は固定長であり、その境界は簡単にオーバーランする可能性があります。 Stringには境界がありません。
- 配列要素は連続したメモリ位置に格納されるため、文字列変数よりも速くアクセスできます。
結論:
文字配列を操作できないことが標準文字列クラスの開発を引き起こしました。
![Webに触発された入れ墨[FUNNY PICS]](https://gadget-info.com/img/social-media/176/web-inspired-tattoos.jpg)