BFSとDFSは、グラフの検索に使用されるトラバース方法です。 グラフ探索は、グラフのすべてのノードを訪問するプロセスです。 グラフは、頂点に接続する頂点 'V'とエッジ 'E'のグループです。
比較表
| 比較基準 | BFS | DFS |
|---|---|---|
| 基本 | 頂点ベースのアルゴリズム | エッジベースのアルゴリズム |
| ノードを格納するために使用されるデータ構造 | キュー | スタック |
| メモリ消費 | 非効率的な | 効率的 |
| 構築した木の構造 | ワイドとショート | 狭くて長い |
| トラバースファッション | 最も古い未訪問の頂点が最初に調べられます。 | エッジに沿った頂点は最初に調べられます。 |
| 最適性 | コストではなく、最短距離を見つけるのに最適です。 | 最適ではない |
| 応用 | グラフに存在する2部グラフ、連結成分、および最短経路を調べます。 | 2辺連結グラフ、強連結グラフ、非巡回グラフ、および位相順序を調べます。 |
BFSの定義
幅優先探索(BFS)は、グラフで使用されるトラバース方法です。 訪問した頂点を格納するためにキューを使用します。 この方法では、グラフの頂点が強調され、最初に1つの頂点が選択され、次にそれが訪問されマークされます。 訪問先頂点に隣接する頂点が次に訪問され、順番にキューに格納される。 同様に、記憶された頂点はそれから一つずつ扱われ、それらの隣接する頂点は訪問される。 ノードは、グラフ内の他のノードにアクセスする前に完全に探索されます。つまり、ノードは、最も浅い未探索のノードを最初に通過します。
例
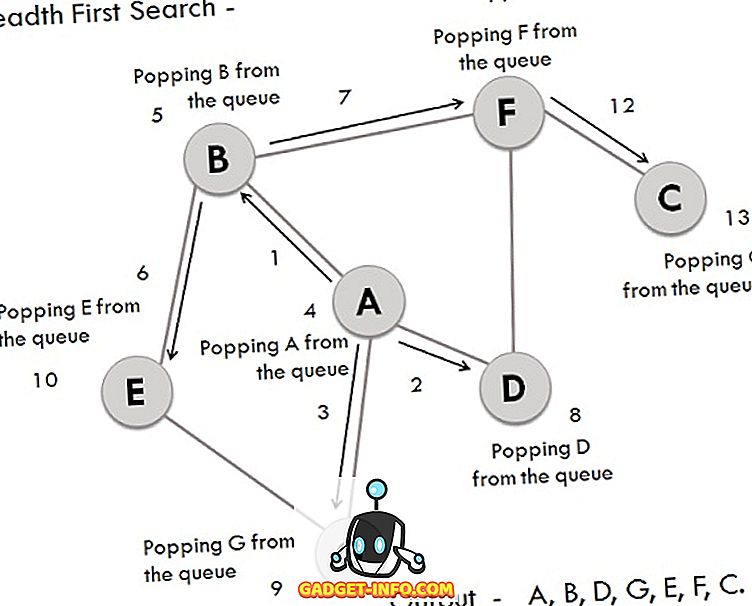
A、B、C、D、E、F、Gを頂点とするグラフがあります。 プロセスに含まれる手順は次のとおりです。
- 頂点Aが展開されてキューに格納されます。
- Aの頂点B、D、およびGの後続要素は展開されてキューに格納され、その間に頂点Aは削除されます。
- ここで、キューのフロントエンドにあるBが、その後続の頂点EとFの格納とともに削除されます。
- 頂点Dはキューのフロントエンドにあり、削除され、その接続ノードFは既に訪問されている。
- 頂点Gは待ち行列から取り除かれ、それは既に訪問された後継者Eを有する。
- ここでEとFがキューから削除され、その後続の頂点Cがトラバースされてキューに格納されます。
- やっとCも削除され、キューも空になったので、これで終わりです。
- 生成された出力は - A、B、D、G、E、F、Cです。

BFSは、グラフにコンポーネントが接続されているかどうかを見つけるのに役立ちます。 また、 2部グラフの検出にも使用できます 。
グラフの頂点が2つの互いに素な集合に分割されると、グラフは2部になります。 2つの隣接する頂点が同じセットに存在することはありません。 2部グラフをチェックするもう1つの方法は、グラフ内の奇数サイクルの発生をチェックすることです。 2部グラフは奇数サイクルを含んではいけません。
BFSは、グラフ内の最短経路をネットワークと見なすことができるという点でも優れています。
DFSの定義
深さ優先検索(DFS)トラバース方法は、訪問先頂点を格納するためにスタックを使用する。 DFSはエッジベースの方法で、頂点がパス(エッジ)に沿って探索される再帰的な方法で機能します。 ノードの探索は、他の未探索ノードが見つかるとすぐに中断され、最も深い未探索ノードが最前面でトラバースされます。 DFSは各頂点を1回だけ通過/訪問し、各エッジは2回正確に検査されます。
例
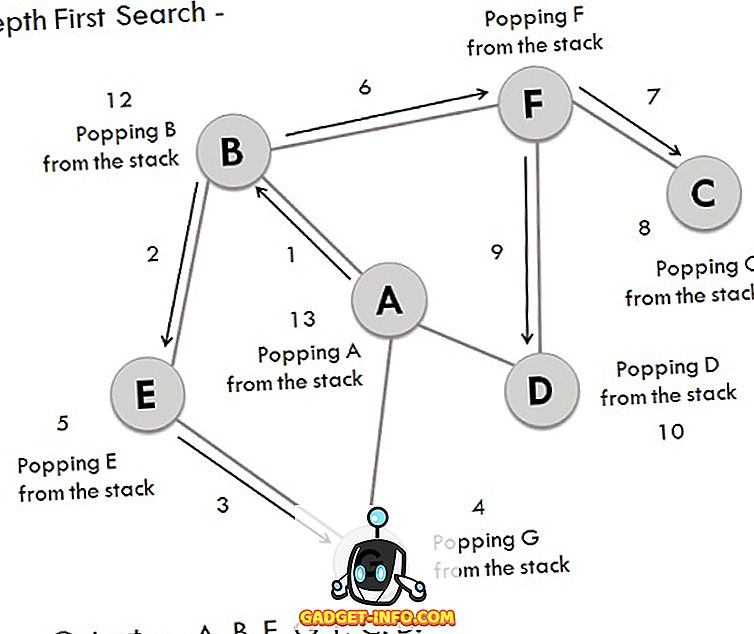
BFSと同様に、DFS操作を実行するために同じグラフを使用することができます。関連するステップは次のとおりです。
- Aを探索してスタックに格納する開始頂点とします。
- AのBの後続頂点はスタックに格納されます。
- 頂点Bには2つの後続要素EとFがあります。それらのうちアルファベット順にEが最初に探索され、スタックに格納されます。
- 頂点Eの後継者、すなわちGがスタックに格納される。
- 頂点Gには2つの接続された頂点があり、両方とも既にアクセスされているので、Gはスタックから飛び出します。
- 同様に、Eも削除されます。
- 今、頂点Bがスタックの最上部にあり、その別のノード(頂点)Fが探索されてスタックに格納される。
- 頂点Fには2つの後続要素CとDがあり、その間のCが最初にトラバースされてスタックに格納されます。
- 頂点Cにはすでに訪問された先行操作が1つだけあるため、スタックから削除されます。
- 今度はFに接続された頂点Dが訪問され、スタックに格納されます。
- 頂点Dには訪問していないノードがないため、Dは削除されます。
- 同様に、F、B、Aもポップされます。
- 生成された出力は、 - A、B、E、G、F、C、Dです。

DFSのアプリケーションには、 2エッジ連結グラフ、 強連結グラフ、 非循環グラフ 、およびトポロジカル順序の検査が含まれます。
グラフは、一方のエッジが削除されてもグラフが接続されたままの場合に限り、2つのエッジが接続されたと呼ばれます。 このアプリケーションは、ネットワーク内の1つのリンクの障害が残りのネットワークに影響を与えず、それでも接続されているコンピュータネットワークでは非常に便利です。
強連結グラフは、順序付けられた頂点のペアの間にパスが存在しなければならないグラフです。 有向グラフでは、順序付けられた頂点のペア間のパスを検索するためにDFSが使用されます。 DFSは接続性の問題を簡単に解決できます。
BFSとDFSの主な違い
- BFSは頂点ベースのアルゴリズムで、DFSはエッジベースのアルゴリズムです。
- キューデータ構造はBFSで使用されます。 一方、DFSはスタックまたは再帰を使用します。
- メモリスペースはDFSで効率的に使用されますが、BFSでのスペース使用率は効果的ではありません。
- BFSは最適なアルゴリズムですが、DFSは最適ではありません。
- DFSは、狭くて長い木を構成します。 反対に、BFSは幅広く短い木を構成します。
結論
BFSとDFSはどちらもグラフ検索の手法は似ていますがスペース消費が異なります。DFSは未調査のノードの単一パスを記憶する必要があるため、DFSは線形スペースを使用します。
DFSはより深い解を生み出し、最適ではありませんが、解が密集している場合にはうまく機能しますが、BFSは最初に最適な目標を検索するのに最適です。