総利益、営業利益、純利益の違い
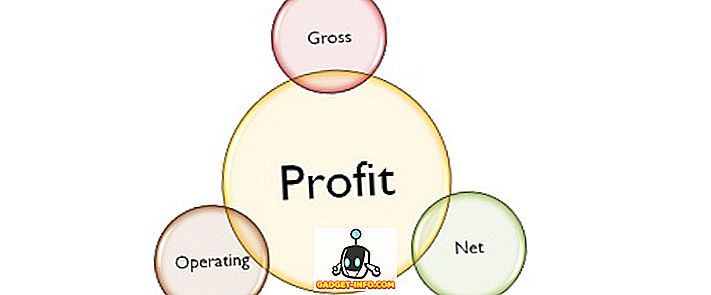
事業は利益を上げることを目的として行われます。 これは、事業年度中に、企業が抱えるリスクと費やされた資源に対するインセンティブとして働きます。 利益は、粗利益、営業利益、純利益に大別できます。 売上総利益 は、製造原価を差し引いた後の収益からの残余額を意味します。 それは生産と価格設定における会社の効率性を示しています。 逆に、 営業利益 は、売上高から製造原価と営業費用を差し引いた後の 利益を 意味します。 それは会社の全体的な運用上の有効性とパフォーマンスを評価するのを助けます。 最後に、 純利益 は、すべての費用、利子、および税金を差し引いた後の、会社に残された利益の金額を表します。 これは、売上を利益に変換する会社の能力の重要な指標です。 与えられた記事を読んで、総利益、営業利益、純利益の違いを理解してください。 比較表 比較基準 粗利益 営業利益 純利益 意味 総利益は、直接経費の支払い後に残された会社の収入です。 営業利益は、営業費用を支払った後に残された会社の収入です。 純利益は、すべての控除後に会社に残された残余収入です。 目的 会社の収益性についてのおおまかな見積もり。 会社がそのリソースを費用にどの程度割り当てているかを知るため。 特定の会計年度に行われた実際の利益を知るため。 利点 余分な費用を管理するのに役立ちます。 不要な運営費を削減するのに役立ちます。 会